 © Copyright: Вы все еще думаете, что Яндекс это поисковая система, которая работает на равных с Google? Нет! Это в основном маркет, такси и прочие деньги. Хотите при бэдовом контенте получить трафик? Платить придется немеряно, потому что ЯДирект – это типовой развод на деньги. © Copyright: Вы все еще думаете, что Яндекс это поисковая система, которая работает на равных с Google? Нет! Это в основном маркет, такси и прочие деньги. Хотите при бэдовом контенте получить трафик? Платить придется немеряно, потому что ЯДирект – это типовой развод на деньги.
Многие желают его создателю почить в бозе, кануть в Лету и прочее, чтобы остался только Гугл. Логичнее пользоваться платными инструментами Яндекса лишь стартапам, продолжая при этом активно работать над содержательным и полезным для людей контентом.
- Почему нужен такой контент? Потому что вопрос интеллектуальной выдачи Яндекс решает последовательно, жестко и быстро.
- Почему быстро? Потому что отстает от Google в этом лет этак на пять и наверстывает упущенное.
- Почему работать над полезным контентом жизненно важно? Потому что вкладываться постоянно в платную рекламу мало у кого хватит бюджета.
- Почему не хватает бюджета? Потому что трафик не есть конверсия.
Как это ярко демонстрируют новые алгоритмы! Начнем разбираться во всех этих "почему"?
Среднее время чтения статьи - 10 минут. С практикой скорочтения - 1 минута. С углублением в тему - 15 минут. С анализом ситуации и переходом по нужным ссылкам - персонально. Погружение в тему принесет доход или разорит при игнорировании проблемы. Выделяйте столько времени, сколько требуется для вашей выгоды.
Ускоренный переход Яндекса к интеллектуальной выдаче
С ощутимым ускорением начала осуществляться поставленная несколько лет назад стратегическая цель Яндекса – ликвидация шлака. Рунетовский лидер догоняет Гугл, ибо некуда деваться: уж больно «грязной» оказалась его выдача на фоне конкурента. Пользователь же стал умнеть на глазах. Он уходит с линк- и прочих помоек сразу.
За Минусинском, который основательно перетряс выдачу, как бы ни сопротивлялись этому факту последователи прежней школы, материализовался фильтрующий Баден-Баден, а чистоту выдачи налаживает Палех. 2 ноября 2016 компания Яндекс анонсировала свой новый алгоритм следующим образом:

Следом, в конце лета 2017 года появился еще более серьезный его последователь - Королев. Если Палех ориентирован только на подзаголовки, то Королев прошерстит весь текст и ничего не оставит без внимания!
- Опять все резко изменилось. Фильтры ужесточились. Под них попадают даже самые продвинутые и «бородатые» порталы.
- Сейчас у многих, кто мониторит выдачу, складывается ощущение, что вообще уже не стоит ориентироваться на ВЧ и даже СЧ просели. Алгоритм включает в работу только НЧ-запросы с длинными хвостами.
Давайте разбираться, чтобы понять, когда и как действительно работает сегодня алгоритм. Сразу отмечу: это не математические вычисления формул, а лишь логика и профессиональный анализ ситуации, процессов поиска информации и ее выдачи. Сталкиваться с этим мне приходится ежедневно и ежечасно, так что есть на чем делать выводы, а уж это я точно умею!
- Что нужно обычному пользователю, который вводит свой запрос? Конечно, ответ на него, максимально подробный и четкий, ведь он за ответом пришел?
- Что происходит, если ответ на выданном сайте не находится? Пользователь видит отсутствие информации сразу, даже без специальной подготовки. Он закрывает сайт и уходит на другой.
- Что делает поисковик, видя, что пользователю сайт неинтересен? Ставит жирный минус. С каждым минусом позиции теряются.
- Что случается, если пользователь задержался, изучил информацию, даже перешел на другие страницы? Появляется жирный плюс. Чем таких больше, тем выше сайт в выдаче.
Это, конечно, примитивно и условно. Алгоритмы куда сложнее! Оценка идет по огромному числу параметров, включая объем текста, но реакция пользователя – один из важнейших, ведь сам поисковый робот читать не умеет. У него есть машинный интеллект, которым его наделили создатели. Определенно, машинный уровень вытекает из уровня разработчиков.
Роботу совершенно все равно, как называет человек запрос – НЧ, СЧ, ВЧ… Более того, выдача может измениться буквально сразу: при повторном запросе через пару минут вы получите другие сайты или другие позиции ранее выданных ресурсов, потому что подключаются разные параметры для оценки запроса.
Для Гугла это давно пройденный этап. Никого такая ситуация там не пугает и не настораживает. Изменение выдачи считается нормой. Всем, кто сейчас пытается это оспорить, отвечу:
- Google в процессе активного приближения к человеческому интеллекту уже свыше 10 лет, именно поэтому его выдача более релевантная и грамотная;
- Яндекс проигрывает потому, что начал облагораживать выдачу примерно на 5 лет позднее, делал это весьма неохотно, долго раскачивался, ну а борьба за выживание заставила ускорить поиски решений и их внедрение.
Сейчас для всех поисковиков не важно множество вхождений точной формы ключей в текст страницы или число употреблений ключевых слов в запросах. Google, как и Яндекс давно ценит качественные полезные тексты, а показателем качества служит лексическое разнообразие.
Что это? А это богатый словарный запас, употребление синонимов и разных словоформ, ну и так далее по списку, то есть то, что способен употреблять настоящий автор, а не сео-копирайтер, ориентированный на робоконтент. Все, что делает статью читабельной, интересной, человечной. Роботизированный текст давно даже роботы не "хавают", как ни старайся!
Новый нейросетевой алгоритм: Яндекс умнеет или поиски по смыслу
Как бы то ни было, но алгоритмы Палех и Королев – очередной этап развития Яндекса. Они еще больше приблизили отклики на запросы к желаемому пользователем результату. Суть их работы схожа с RankBrain - частью сложного поискового алгоритма Google, программой, которая отбирает наиболее релевантные конкретным запросам страницы из миллиардов прочих.
RankBrain – это название гугловской системы искусственного интеллекта. Создавали ее на базе алгоритмов машинного обучения. Именно поэтому ее, а теперь и алгоритмы Яндекса, называют обучаемыми. RankBrain, Палех и Королев по действию напоминают Word2Vec: они помогают обрабатывать результаты поиска, распознавая связи понятий, а не просто словосочетания.
- Столкнувшись с незнакомыми моментами, обучаемая система ищет синонимы, подсказки, анализирует их, делает выводы и запоминает.
- Аналогии становятся основой следующей фильтрации результата.
- Алгоритм сопоставит поведенческие факторы пользователей сети, соотнесет их с результатами, отсортирует в поисках наиболее релевантного.
Собственно, мозг человек разумного действует аналогичным образом. В схожести работы систем отбора двух поисковых лидеров нет ничего удивительного.
- Машину разными способами учат правильно, «по-человечески» воспринимать информацию.
- Человек свои запросы составляет с длинными "хвостами" и всегда хочет получить по ним релевантные результаты.
По статистике самого ведущего рунетовского поисковика, ежедневно обрабатывается около 280 тысяч поисковых запросов пользователей. Около 40% из них – низкочастотники.
Сноска: Word2Vec - инструмент (набор алгоритмов) для расчета векторных представлений слов. Он реализует две архитектуры — Continuous Bag of Words (CBOW) и Skip-gram плюс дополнения. На вход для оценки подается корпус любого текста, а на выходе получается набор векторов слов. Если кому-то опять непонятно, простите, дальше расширять информацию не могу. Милости прошу в Гугл или Яндекс.
 Продолжаем логическое расследование. Владелец сайта, собственно, хочет получать по любому заходу высокий отклик – процент конверсии, а по НЧ он самый-самый! Очевидно: хвосты определяют готовность пользователя стать заказчиком, совершить нужное действие. Так ловите свою жар-птицу за хвост! Продолжаем логическое расследование. Владелец сайта, собственно, хочет получать по любому заходу высокий отклик – процент конверсии, а по НЧ он самый-самый! Очевидно: хвосты определяют готовность пользователя стать заказчиком, совершить нужное действие. Так ловите свою жар-птицу за хвост!
- Когда пользователь пишет высокочастотный запрос, он еще только в начале пути и будет долго по нему идти к истине, изучая информацию. Речь идет о разумном пользователе, а сегодня таких – большинство.
- Ну и кому нужны эти ВЧ, за которые приходится платить так дорого? Вы в ТОПе по ним? У вас шикарный трафик? А все лавры достаются тому, кто стоит в конце пути - владельцу сайта, разместившему полезный контент с "хвостами". Он-то и радуется высокому проценту конверсии, потирая руки и считая барыши!
- Как это происходит? Примерно так:
- пользователь пишет ВЧ-запросы и попадает к тем, кто выдается по ним за деньги;
- смотрит, что предлагают в сети, и сравнивает;
- определяет для себя узкий круг предложений;
- вписывает запрос по этому кругу;
- получает более узкий ответ (СЧ) и анализирует его;
- сводит поиск к паре вариантов, потом к одному;
- ищет этот один (НЧ) среди предложений уже по сочетанию своих приоритетных параметров.
- Пройдя долгий путь, пользователь понимает, что именно ему требуется. Так и появляются «хвостатые» запросы, а робот выдает ответ по узкому поиску – сайты, на страницах которых эти запросы встречаются.
ВСЁ ПРЕДЕЛЬНО ПРОСТО И ЛОГИЧНО! Палех и Королев ориентированы на хвосты. Это означат, что новые алгоритмы улучшают выдачу по «хвостатым» НЧ-запросам. Клювик и туловище жар-птицы, т. е. ВЧ и СЧ-ключи, их не колышут.
Если кто-то не в курсе, опять расшифрую: статистические данные когда-то подвели разработчиков Яндекса к решению разделить все запросы на три категории. Для наглядности их изобразили в виде жар-птицы:
 клюв - короткие ВЧ-запросы, малая часть общей массы, а потому – только клюв; клюв - короткие ВЧ-запросы, малая часть общей массы, а потому – только клюв;- туловище - более длинные СЧ-запросы, с некоторыми уточняющими словами, но уже редкие;
- хвост - совсем редкие, сложные, часто не повторяющиеся НЧ-запросы, состоящие из многих слов, словосочетаний, потому что каждый пользователь мыслит по-своему.
Упс, хвостатых реально много! По количеству их больше всего, а по результативности у них самый высокий процент конверсии. На хвосты и дает релевантные ответы новый алгоритм.
Правильнее будет уточнить: изысканный и узорчатый Палех и его последователь Королев не сменили Минусинск. Они были созданы ему в помощь, как и технологии машинного обучения «Матрикснет».
- Напомню для непосвященных в тему: этот механизм направляет робота на сайты, получившие высокую оценку асессоров - реальных людей, от которых зависит позиция сайта после его проверки "вручную" (институт асессоров появился у Яндекса примерно 7 лет назад, одновременно с введением первого самообучающегося алгоритма ранжирования).
- Такой порядок действия позволяет научить машину вычленять незаметные взгляду человека факторы, подтверждающие ценность текстового контента.
Впрочем, Палех и Королев функционируют не только на низкочастотниках, но и на всех типах ключей, просто больше ориентированы на отслеживание именно редких запросов. По заявлению самих разработчиков, которое было сделано еще в начале ноября 2016 года, новый, нейросетевой подход:
- позволяет поиску Яндекса точнее понимать, о чем его спрашивают люди;
- лучше находить веб-страницы, соответствующие запросам не только по ключевым словам, но и по смыслу.
За сопоставление смысла запросов и документов отвечает поисковая модель на основе нейронных сетей (читайте ниже).
Запросы из длинного хвоста разнообразны, но их группируют по параметрам в категории. Есть запросы от взрослых, детей, людей, которые ищут по каким-то эпизодам или известным словам песни, книги, фильма и так далее.
Конечно, работа нейросетевого алгоритма строится на накопленных разработчиками знаниях о поведении пользователя, статистике, аналитике. Чем больше знаний и выше ориентированность на человека, тем лучше становится выдача. Очевидно, что наиболее сложной она будет именно по хвостатым запросам. Почему?
- Совершенно невозможно предусмотреть, что именно напишет уже имеющий некую информацию пользователь.
Уникальные запросы не попадают ни в какие списки типа Wordstat, а ведь именно такие заходы и нужны владельцу сайта. Мы это выяснили выше.
После введения в действие нейросетевых алгоритмов маркетологи, сео- и веб-мастера, прочие специалисты уже не раз провели на практике, схожесть их работы с RankBrain. Палех проигрывает пока во всех раундах битвы роботов-интеллектуалов, но действительно выдает релевантные ответы, хоть и чуть ниже по позициям.
- Скорее всего, это связано даже не с недоработкой программы, а с желанием заработать как можно больше на топовых позициях.
- Туда по-прежнему попадают сайты и вовсе без текстового контента. Просто потому, что позиция проплачена.
- Разумный пользователь, закормленный рекламой по уши, думает: когда же найдется волшебник, который остановит этот "варящий кашу горшочек"? Пока не нашелся - просто пропускает первые позиции, переходя сразу к 7-8-9-10-й и далее.
Королев еще обкатывается, но уже проявляет себя весьма активно. В любом случае, Яндекс по-прежнему хочет зарабатывать. Просто немного стало перевешивать желание прилично выглядеть на фоне основного конкурента.
Не будем забывать и о том, что это только начало его работы, а оба инструмента у ведущих поисковых систем были созданы как самообучающиеся. Учитывая скорость движения Яндекса к своим стратегическим целям, не исключено, что он быстро догонит Google.
Матрикснету не справиться без помощника: зачем нужен нейросетевой алгоритм
Когда пользователь вводил запрос в прежние времена, все было ясно: на подносе выдачи он получал блюда из меню по написанным в строке поиска словам, тем, из которых строилась запросная фраза.
- При ВЧ-запросах, как правило, находилось все, что нужно в ТОП-50. Далее смотрели только самые дотошные аналитики. Остальные пользователи считали, что дальше - черная дыра.
- По сложным (хвостатым) запросам полезную информацию найти быстро не удавалось, а часто не удавалось вовсе.
Матрикснет создали для стартового понимания пользователя. В поисках релевантного ответа на запрос, этот инструмент использует так называемую «мудрость толпы» или «массовый психоз». Кому как нравится!
В любом случае в основе поиска программы лежит массовость: большинству пользователей нравится выданный в ТОПе сайт, значит, он релевантный. Не важно, что ответ так и не был найден, потому что надоело копаться по этим сайтам с ВЧ-ключами!
Все было бы предельно просто, но ответ с ВЧ-запросами куда проще, чем с НЧ. Авторов последних Матрикснету не понять, а их так много! Как строится вывод программы? Очень просто:
- пользователи искали ответ, перешли в выдаче на сайт, дальше не искали, сидели там долго, значит, все им понравилось;
- выдам-ка я, значит, и всем остальным тот же сайт, потому что я решил, что он подходит.
Некоторые НЧ-запросы настолько уникальны, что вообще не повторяются. Значит, всех под одну гребенку? Палех положил конец тратам времени пользователя на поиски путем введения вариантов запросов (и они, кстати, успехом заканчивались редко).
Технология нейронных сетей изменила ситуацию с поиском. Теперь каждый пользователь может ожидать быстрого отклика поисковика и выдачи релевантных сайтов, если не на 100, то хоть на 80% соответствующих запросу. В Яндексе это происходит сегодня благодаря алгоритму Палех.
Что же делать с любимым SEO
Запуск интеллектуальных алгоритмов Гугл и Яндекс меняет реалии в сфере SEO. Этого следовало ожидать.
- RankBrain - уже третий по важности сигнал даже не ветра, а штормового предупреждения и цунами в ранжированиии.
- Палех присоединился к RankBrain. Минусинск стал для многих катастрофой вселенского масштаба.
- Теперь у владельцев сайтов, которые изначально продумывали полезность текстового контента для читателя, а не робота, появилась возможность выдаваться в ТОП по запросам без всякой рекламы.
Чтобы оптимизировать контент под эти две интеллектуальные системы, надо всего лишь писать СДЛ - статьи для людей! Именно так их назвали. Этот термин появился много лет назад. Он обозначает тексты, написанные на понятном не для профессионалов сферы или роботов, а для целевой аудитории владельца сайта языке - языке обычного человеческого общении, конечно, с учетом специфики и терминологии сайта. При наличии СДЛ:
- пользователь продемонстрирует роботу свою лояльность к ресурсу;
- владельцу сайта не потребуется слушать про какую-то мистическую оптимизацию и формулы, танцевать под шаманские бубны.
В том, что писать следует для целевой аудитории, уже много лет никто не сомневается, ведь суть Интернет-ресурса, который вы создаете, - польза для ЦА с выгодой для вас. Помните: основное - это смысл вашего текста.
Не ключи, не комбинации запросов, не их вариации с синонимами, а смысл и польза! Только с ними вы завоюете вашу целевую аудиторию. Игнорировать тенденции развития поисковых систем мог только слепец и человек, целенаправленно гнувший свою сео-линию, ведь они, эти тенденции укладывались в разумную логику.
- Уже более 15 лет тому назад Гугл заговорил о том, что идет именно к такой "полезной" выдаче, и более 10 лет назад он осуществил задуманное, продолжая совершенствовать систему.
- Уже более 10 лет назад Яндекс заявил о своем намерении кардинально изменить алгоритм, более 5 лет, как он осуществляет задуманное и продолжает еще активнее совершенствовать свой новый подход к выдаче.
Тот, кто не прислушивался в свое время к разумным доводам об LSI-копирайтинге (это не просто термин, а подход к написанию текстов, так что не доверяйте тем, кто размахивает им, как флагом на баррикадах - многие даже не понимают, в какие цвета он окрашен) и создании полезного текстового контента на собственном сайте, потерял все:
- вложения в пустые сеошные статьи под анкоры, размещенные на сторонних ресурсах (а многие заказывали по 1000 и более таких статей, игнорируя наполнение собственного ресурса);
- позиции, достигнутые с помощью ссылочной массы и битком набитых прямыми-кривыми сеошными запросами собственных страниц (такие сайты сегодня пессимизированы - под фильтрами и банами).
Чего мы, копирайтеры, только ни пережили за годы модернизации роботов! Для тех, кому интересно, алгоритмы ранжирования Яндекса с 2007 года:


Параллельно алгоритмам постоянно велась работа над созданием санкционных программ. Все они направлены на вскрытие обманных техник. Таковые усиленно изобретали и применяли сео- и веб-мастера, дабы обойти алгоритмы и продвинуть сайты. За деньги, конечно.
Сегодня фильтры стали особенно жесткими. Обойти их сложно даже самым продвинутым спецам. Часто доходит до полного и окончательного бана ресурса - нового и старого, мощного и примитивного. Опять же, для тех, кому интересно:


Если сайт попал под фильтры или даже один фильтр - это очень плохо. Он слетает с выдачи. Для снятия санкций придется основательно потрудиться, так что лучше изначально не нарушать правила игры. "Тебя посодют, а ты не воруй!" (С).
Важно! Если с отфильтрованного сайта ссылка ведет на ваш сайт, вас тоже "зацепит", пусть не так сильно, не до бана, но позиции понизятся, поэтому не рискуйте сегодня с массовыми ссылками на ресурсах, созданных под трафик.
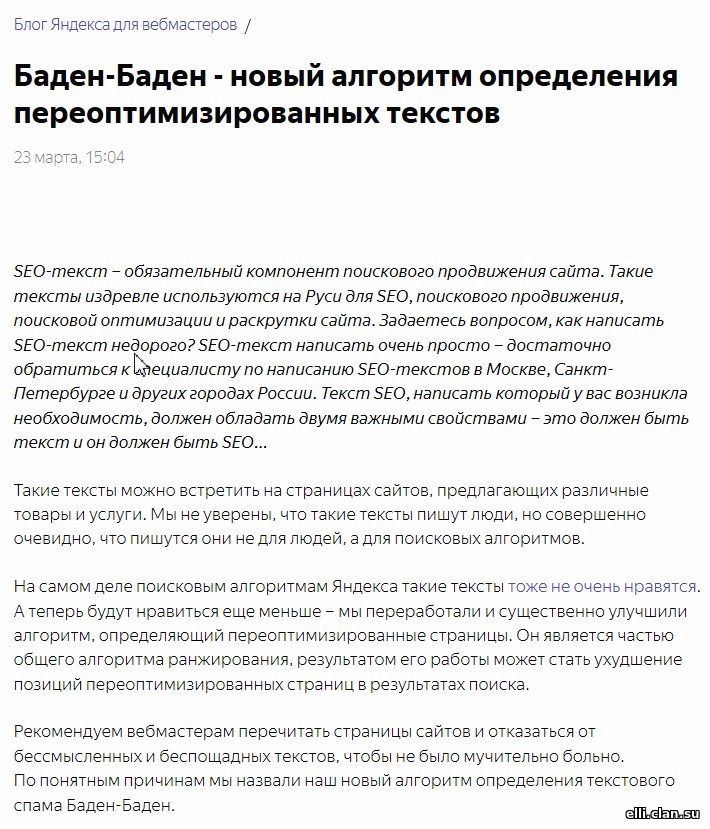 Последний алгоритм пессимизации, который наделал много шума в сео-среде - Баден-Баден. Может называть его старым, добрым термином "переспам". Да, он фильтрует именно за переспам, причем фильтрует каждую страницу, а не только сайте в целом. Если сайт нормальный, а какие-то страницы переспамлены, они в выдачу не попадут. Последний алгоритм пессимизации, который наделал много шума в сео-среде - Баден-Баден. Может называть его старым, добрым термином "переспам". Да, он фильтрует именно за переспам, причем фильтрует каждую страницу, а не только сайте в целом. Если сайт нормальный, а какие-то страницы переспамлены, они в выдачу не попадут.
- С марта 2017 года так называемые "переоптимизированные" тексты отправляются на задворки выдачи.
- Всем вебмастерам рекомендуется "перетрясти" страницы сайтов, выкинуть беспощадно набитые запросами тексты, в которых много повторяющихся ключевых слов и неестественных речевых оборотов, но мало полезной информации, или хотя бы убрать часть ключей, заменить на синонимы, литературно "причесать" статьи.
- Такие тексты, создаются с целью повлиять на позиции сайта в поисковой выдаче, теперь понижают эти самые позиции.
- Стоит забыть и про математику в текстах - количество и тип вхождений, тошноту, уровень плотности и прочее.
- Даже процент уникальности не надо подгонять к сотне, если он равен 75-95% в конкурентных нишах. Это нормально. Все уже миллионы раз сказано и написано. 100% - это показатель искусственности, если ваш текст не несет нужную нагрузку, не имеет смысл и не полезен для людей.
Выдача строится независимо от цифр и указанных запросов. Она зависит только от интеллекта автора, уровень которого легко определяет робот. С этим у машины давно нет проблем. Ведь вы же больше не видите в выдаче пустые, водные, 10-рублевые анкорные статейки по 2-2,5 тысячи символов?
Если вы решили провести аудит сайта и попробовать удалить ошибки общей оптимизации самостоятельно, присылайте запрос на моей е-мейл j-elenochka@yandex.ru или в скайп J-Elenochka. Вышлю подробную инструкцию, что и как можно попробовать оценить и исправить. Единственное, что не советую изменять самостоятельно, так это тексты. На них сейчас завязано все.
Искусственные нейросети: технология машинного обучения или семантический подход к выдаче
Попытаемся понять, как попасть в релевантную выдачу с размещенным на страницах текстом, чтобы получить отличные результаты работы контента. Попытаемся понять искусственные нейронные сети или нейросети. Надеюсь, наш интеллект нам это позволит сделать?
- Нейросети одна из технологий машинного обучения, наиболее популярная в последние годы движения к интеллектуальной выдаче.
- Едва появившись, искусственные нейронные сети продемонстрировали удивительные результаты.
- Анализировать с их помощью робот стал не только текстовый контент, но даже фото, видео, аудио.
- Тестирование нейросетей современного уровня позволяет с уверенностью сказать: возможен анализ любой информации, называемой «естественной», и выдача наиболее релевантного ответа на запрос пользователя.
Поскольку тексты анализировать проще всего, они и являются основным объектом для интеллектуального робота. Как утверждают маркетологи и сами разработчики программ обучения роботов, в обозримом будущем выдача будет оставаться текстовой, т. е. на основе анализа текста. Он – в зоне повышенного внимания и риска для владельцев сайтов.
Работа над совершенствованием нейросетей активно продолжается. Первое, на что обращает внимание современный робот – смысловое соответствие запроса заголовку страницы. Метатеги по-прежнему важны, но далее обучаемый поисковый модуль реагирует на поведении пользователей, попавших на страницу.
- Поскольку робот действует не в сфере букв, а в сфере чисел, нейронная сеть сравнивает именно их, но предварительно переводит буквы в цифры.
- В отличие от привычного нам двухмерного и даже трехмерного пространства, сегодня координаты пространства для роботов Яндекса 300-мерные, т. е. созданы группы из 300 чисел, каждое из которых – 2-осная координата или точка на плоскости.
Запрос пользователя и отклик системы робот просто совмещает по координатам. Если они близки друг к другу, как, например, Россия и Москва, Германия и Берлин, Китай и Пекин, робот не пропустит ассоциацию. Страница будет выдана по запросу даже в том случае, если пользователь не ввел в строку поиска название столицы/страны.
- Искусственная нейронная сеть поможет совместить набранное пользователем слово с другими, присутствующими на странице.
Семантика (читай «смысл») как раз и дает наилучшие показания выдачи при «длиннохвостом» запросе, даже если ни одно слово в тексте и ключе не совпадают! Вот это и есть основное отличие интеллектуальной выдачи от прежней, сеошной. Именно поэтому можно писать в запросе «бла-бла-бла любые слова» и получать текст нужной песни или формулу успеха, даже не зная ее составляющих.
«Главное, чтобы костюмчик сидел!» (С), ну, то есть чтобы работало без сбоев в настоящем и будущем. Раньше требовалось указывать в метатегах возможный максимум ключей. Теперь это даже критично. Более того, уважаемые дамы и господа сеошники, есть риск переспамить страницу и попасть под фильтры.
- Обращаю на это особое внимание владельцев сайтов.
- Настало время перемен!
- Семантический поиск работает везде, по всей странице.
- Факторов ранжирования прибавилось, как и их комбинаций!
Не пытайтесь впихнуть все в тайтл и дескрипшен, "обогатить" текст одними и теми же словами в разных вариациях. Этим вы только повеселите разработчиков Палеха и создадите очередной прецедент в категории санкций. Алгоритм не полагается только на соотношение в цифре запроса и метатегов.
Каждое слово и словосочетание в статье попадает "под колпак" робота при проведении анализа. Нет необходимости по всему тексту писать одно и тоже: купить, продать, цена, стоимость, акции, скидки, распродажи. Достаточно одного упоминания, чтобы машина слово нашла и соединила его с другими, сопоставив с запросом пользователя. Фильтры успешно борются с переспамом и нечитабельностью текстов, битком набитых одними и теми же фразами. Аллилуйя!
Внутри ранжирования есть свое ранжирование, и параметров там очень много! Семантический анализ насчитывает до 1000 факторов. Окончательное решение, что именно применять, принимает Матрикснет, который, как утверждают разработчики, за гулом двигателя самолета различит голоса людей в салоне.
Можно ли обойти алгоритмы поисковых систем сегодня
У отечественных веб-мастеров и сео-специалистов всегда в голове сидит мысль: накрутить, обмануть и уничтожить. Ну, что ж! От этого не уйти. Вечно кто-то делает ставку на интеллект и образование, рост и совершенствование, а кто-то на обход норм и законов. Попытка - не пытка. А есть ли смысл лезть через забор при наличии незапертой калитки?
После запуска Палеха и Королева у честных оптимизаторов и владельцев сайтов появились опасения, что недобросовестные сеошники начнут размножать страницы, оптимизировать их под НЧ-запросы.
- Какими вложениями это попахивает? Ведь сколько пользователей, столько и мыслей.
- Можно ли под каждую создать страницу? Вряд ли.
- С другой стороны - почему бы и нет? Лишь бы контент этой страницы оказался полезным, а вложения - рентабельными.
Прежде чем искать обходной путь, просчитайте возможный доход. Скорее всего, вы поймете, что лучше идти прямой дорогой. Если вспомнить о сути новых алгоритмов, то созданы они для продвижения полезных и сайтов с качественным контентом. Вот и дайте такой вашей целевой аудитории.
- Все просто и совсем недорого с учетом, что в полезный контент вы вкладываете деньги один раз.
- Больше не придется платить ежемесячно круглую сумму за покупку топовых позиций.
Большинство пользователей даже не в курсе, что они внедрены, эти Палех и Королев. Всем, кто вписывает что-то в строку поиска, важно, что в выдаче они получат не то, что было оптимизировано под какие-то там ссылки и продвинуто какими-то там ссылочными массами или проплатой позиций. Они хотят получить то, что они ищут, и получают.
Общая оптимизация сегодня никуда не делась. Она нужна, просто одной ее недостаточно. Даже если ее нет, но контент релевантен, страница появится в выдаче по запросу пользователя.
- Не надо попугайно впихивать одно и тоже в тексты, делая их нечитаемыми.
- Надо писать интересно, писать для людей, без вранья и "клиники" Главреда.
Алгоритм не продает, если кто-то не понял его сути. Он только выдает по запросу. Палех позаботится о появлении ваших полезных статей перед пользователем, ну а вы уж позаботьтесь о том, чтобы этот пользователь от вас просто так не ушел, чтобы стал клиентом.
- Тут алгоритм никому не поможет, если не продумана продающая составляющая статьи и доказательная база.
У вас есть сайт или вы планируете его создать? Изучайте проблемы и запросы вашей целевой аудитории. Делайте ресурс максимально удобным и полезным для нее. Избегайте ошибок ваших предшественников. Работайте по всем направлениям оптимизации, потому что никто не отменял прочие факторы ранжирования. Нужна не только полезность информации на страницах Интернет-ресурса, но и многое другое.
© Copyright: Автор статьи - Котова Елена, профессиональный копирайтер.
Сотрудничаю напрямую (скайп J-Elenochka, е-мейл j-elenochka@yandex.ru) или на биржах Кворк, Etxt , Копилансер, нейминга и слоганов.
Читайте также:
Соцсети, группы, сообщества, SMM-маркетинг без прикрас: уровень манипуляций сознанием или кому нужны бесперспективные маркетинговые ходы
Ошибки лендингов: почему до 90% одностраничников неэффективны
Басня про блондинку и интеллектуальный конкурс
О семантическом ядре, поисках и происках: дайте конкретику для получения результата
Пресс-релиз - имиджевый документ под инфо-повод: особенности создания, размещения и вся правда о подводных камнях процесса
Эффективное коммерческое предложение: как создать и что сделать, чтобы не послали по факсу
Оптимизация сайта и контента или как не докатиться до переоптимизации, фильтра и бана в конце II десятилетия XXI века
Какого размера должна быть статья для сайта: при ранжировании размер текста имеет значение
Главред – польза или вред: вольные рассуждения на тему для поклонников системы проверки и тех, кто хочет ими стать
Контент-маркетинг в каждой сфере или зачем нужны статейные разделы с полезным, релевантным контентом
За кулисами полезного контента: на какие ухищрения и уловки идут дельцы от продвижения для расширения трат владельцев сайтов
Копирайт или копирайтинг: суть и различие. Не пропустите еще одну степень защиты вашего контента
Минусинск - новый алгоритм Яндекса, пессимизирующий за SEO-ссылки: почему он появился и как действует очередное отключение ссылок
Коммуникативная грамотность - что это? Как определить, кто писал текст и выявить ошибки
На правах подведения итогов о текстовом контенте 2016-2017: про изменения, произошедшие в сфере копирайтинга за последние пять лет
Копирайтинг как профессия: все, что вы хотели знать о написании рекламных и сео-текстов, а также о тех, кто способен их создавать
Часть 3. Интеллектуальный контент 2016-2017: магический кристалл, танцы с веером или формулы рекламного копирайтинга
Часть 2. Интеллектуальный контент 2016-2017: какие тексты сегодня любят роботы
Часть 1. Интеллектуальный контент 2016-2017: профессиональный взгляд на продающие тексты - мифы и реальность, тенденции и изменения
Маркетинг кит, он же marketing kit, он же маркетинг-кит: секреты нового инструмента маркетолога
LSI-копирайтинг и роль копирайтера: формируйте контент будущего уже сегодня
Правила размещения контента на странице
Бескрайний океан копирайтинга: как не ошибиться с выбором авторов на биржах контента
Статья о компании: каков он, этот имиджевый монстр
Для главной страницы: продающие и мотивирующие тексты - как заказчику оценить профессиональную грамотность копирайтера
Что такое Landing Page или лендинг: стоит ли экономить на успехе бизнеса
|